Unlocking the Power of Off-Policy AI Training Algorithm
In the realm of Artificial Intelligence (AI), Reinforcement Learning (RL) has emerged as a crucial framework for training intelligent agents to make decisions in complex environments. At the heart of RL lies the concept of Off-Policy AI Training Algorithm, which enables agents to learn from historical data, simulations, or data generated by other agents, thereby enhancing learning efficiency and potentially accelerating the training process.
What is Off-Policy AI Training Algorithm?
Off-Policy AI Training Algorithm is a paradigm that allows an agent to learn about an optimal policy while following a different, more exploratory one. This separation of the policy being learned from the policy used for generating experience unlocks significant flexibility, enabling agents to learn from diverse sources of data. By leveraging off-policy learning, agents can learn from historical data, simulations, or data generated by other agents, which can be used to improve the learning process.
Benefits of Off-Policy AI Training Algorithm

Types of Off-Policy AI Training Algorithm
There are several types of off-policy AI training algorithms, including:
- Q-Learning: A popular off-policy algorithm that learns an optimal action-value function using a Q-function.
- Deep Q-Networks (DQN): A type of Q-learning that uses a deep neural network to approximate the Q-function.
- Proximal Policy Optimization (PPO): A first-order model-free off-policy algorithm that combines advantages of trust region methods and deep RL.
- Deep Deterministic Policy Gradient (DDPG): A model-free off-policy algorithm that leverages actor-critic methods to train policies in continuous action spaces.
Challenges and Limitations of Off-Policy AI Training Algorithm
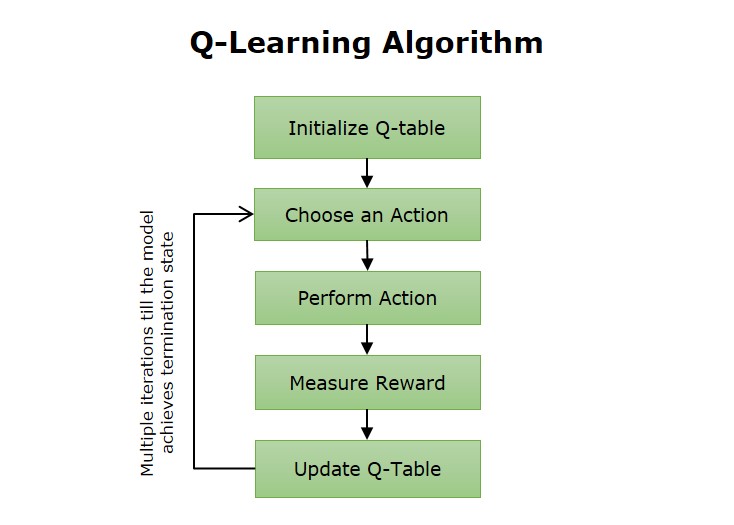
This particular example perfectly highlights why Off-Policy Ai Training Algorithm is so captivating.
While off-policy learning offers numerous benefits, there are also several challenges and limitations to consider:
- Proxy Rewards: Off-policy learning may require the use of proxy rewards, which can lead to reward mismatch and decreased performance.
- Partial Observability: Off-policy learning can be sensitive to partial observability, where the agent has limited information about the environment.
- Data Preparation: Off-policy learning requires careful data preparation, including preprocessing, filtering, and normalization of the data.
Conclusion
Off-Policy AI Training Algorithm has emerged as a crucial paradigm in the field of Artificial Intelligence, offering numerous benefits, including improved learning efficiency, flexibility, scalability, and cost-effectiveness. However, there are also several challenges and limitations to consider, including proxy rewards, partial observability, and data preparation. By understanding the mechanisms and limitations of off-policy learning, researchers and practitioners can unlock the full potential of this powerful approach and develop more efficient and effective AI systems.










